
DeepSeek是一款基于AI技术的智能搜索引擎,结合深度学习与自然语言处理,提供精准、高效的搜索体验。探索DeepSeek,感受未来智能搜索的无限可能!尽管我国在算力上要落后于美国,但DeepSeek融合多种创新技术突破算力瓶颈,引入“多头潜在注意力(MLA)”和“混合专家架构(MoE)”等优化Transformer架构降低算力需求;采取“FP8混合精度训练”和“多偶流水线机制(DualPipe)”提升GPU芯片利用率;使用强化学习技术训练模型推理能力,实现与OpenAI o1模型相当的推理能力。但目前DeepSeek模型“幻觉率”高于GPT同类型模型,后续仍需降低幻觉率,中国大模型正逐步缩小与美国的差距,同时受益于工程师红利,我国在人工智能+应用场景开发上领先美国,中国人工智能技术将与美国并驾齐驱,增强中国自主可控发展人工智能的信心。
DeepSeek将繁荣智能终端产品创新与消费。智能手机、电脑等终端产品正面临创新瓶颈,消费者更换周期拉长使相关产品消费需求乏力。通过与手机、电脑等终端产品融合,人工智能将成为个人的生活助手,将促进手机、电脑等产品更新需求。同时,人工智能与汽车、人形机器人结合将创造新的产业。预计2025年中国自动驾驶市场空间290亿美元,到2030年中国自动驾驶市场空间将达6390亿美元,年复合增速85%。尽管人形机器人产业尚处于前期阶段,DeepSeek模型在感知、决策和行动等方面对人形机器人的发展起到了重要的推动作用,且其模型高效性特点也更易于部署在人形机器人硬件平台,加快人形机器人商业化进程。
DeepSeek通过软件算法创新突破算力瓶颈,特朗普2.0可能进一步收紧GPU芯片对华出口,对中国人工智能产业实施全面封锁。面对特朗普2.0加码科技封锁,从中央到地方推出支持政策助力产业发展,将人工智能定位为驱动未来产业变革的核心力量;京津冀、长三角和珠三角地区也出台各自专项扶持政策。2025年及其后可能进一步出台相关支持政策,支持技术研发的政策,聚焦高端芯片、核心算法等关键短板领域;完善数据法规,进一步细化数据分级分类管理标准;人才培养与引进政策,推动高校加速人工智能学科建设。目前,以华为昇腾和寒武纪为代表的国产AI芯片正逐步成熟,保障中国人工智能发展硬件基础。
人工智能发展也带来了部分社会问题,如对就业市场的冲击、道德与法律难题、数据安全与个人隐私问题、互联网虚假信息泛滥等。2024年上半年人工智能岗位需求大幅增长,如深度学习岗位同比增加61%,但对编辑/翻译等易于数字化的岗位影响较大,主要集中在白领岗位;而对生产制造、生活服务等相对不易于数字化的岗位影响较小,但随着DeepSeek模型逐渐在工业生产领域落地,产品质量检测类生产制造岗位将率先受到冲击。同时,人工智能发展也带来了道德与法律难题,确定责任归属变得异常复杂;对数据安全与个人隐私造成威胁,人工智能强大的生成能力,使得虚假信息的制作和传播变得更加容易和高效以及加剧互联网虚假信息的泛滥。
建议从以下四个方面出台相关产业政策保障人工智能可持续发展。一是持续加大对先进制程半导体的研发支持;二是加强人才培养与引进,优化科研环境;三是加强职业教育培训体系建设并完善社会保障体系;四是通过立法加强对数据信息与隐私监管。
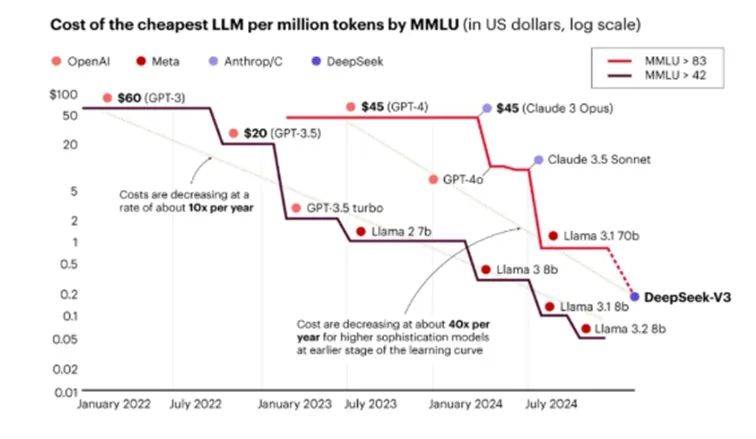
人工智能发展的关键要素是数据、算力和算法,因美国对我国禁运高端GPU芯片,原先产业共识认为我国人工智能技术水平将受限于算力不足,与美国的差距将逐步扩大,但DeepSeek通过模型算法创新,在相对较低的算力资源上,实现与OpenAI媲美的大模型性能水平,且成本远低于OpenAI。DeepSeek的横空出世证明,即使我国GPU芯片落后于美国,但通过软件算法创新,仍能在大模型技术性能上缩小与美国的差距,同时受益于工程师红利,我国在人工智能+应用场景开发上领先美国,中国人工智能技术将与美国并驾齐驱,提升发展自主可控的人工智能产业信心。
幻觉是指模型生成看似合理但实际上与事实不符、无中生有或自相矛盾的内容,在Vectara HHEM人工智能幻觉测试(行业权威测试,通过检测语言模型生成内容是否与原始证据一致,从而评估模型的幻觉率,帮助优化和选择模型)中,通用大模型V3的幻觉率是3.9%,高于同类型的GPT-4o 1.5%的幻觉率,推理模型R1的幻觉率是14.3%,高于同类型GPT-o1的2.4%,其他测试标准中,DeepSeek模型幻觉率也高于GPT同类型模型。我们认为,DeepSeek模型幻觉率较高可能与其低精度训练、给予模型更多创造性奖励等有关,后续DeepSeek需降低模型幻觉率,如针对不同类型任务做更精细地训练、引入检索增强生成(RAG)技术,通过将外部知识库与大语言模型相结合,在模型生成文本时,从外部知识库中检索相关信息并融入生成过程,从而提升生成内容的准确性、时效性与专业性。
面对算力资源远低于海外大模型企业的状况,DeepSeek引入“多头潜在注意力(MLA)”和“混合专家架构(MoE)”等优化Transformer架构降低算力需求;采取“FP8混合精度训练”和“多偶流水线机制(DualPipe)”提升GPU芯片利用率;使用强化学习技术训练模型推理能力,实现与OpenAI o1模型相当的推理能力。
DeepSeek-V3模型创新优化Transformer架构,引入“多头潜在注意力(MLA)”和“混合专家架构(MoE)”降低算力需求,训练成本仅为同类闭源模型的1/20。标准的注意力机制随着模型规模的增加,键值的缓存需求急剧增长,可能会因内存占用过高而导致计算效率低下。多头潜在注意力机制通过低秩联合压缩注意力的键值,将高维的键值映射到低维的潜在向量空间,但仍包含了输入的关键信息,显著减少键值缓存内存占用,降低约80%。在每个注意力头得到潜在向量后,通过多头并行计算,每个注意力头关注输入序列的不同部分,最后将多头输出进行拼接组合成最终的输出。同时,为了提高模型训练的效率和性能,DeepSeek-V3模型引入多Token预测(MTP)技术,传统的单Token预测训练每次只预测下一个Token,MTP技术则同时预测多个Token,训练时间能缩短20%-30%,且能更精准捕捉上下文语义关系,生成更准确、更连贯的文本。
混合专家架构(MoE)将模型分解为多个“专家”网络,每个专家网络都是独立的子模型,专门负责处理特定类型的输入。当输入数据进入模型时,由一个门控网络根据输入数据的特征,动态地将其分配给最合适的专家网络进行处理。MoE架构的稀疏激活机制使得每次只有部分专家被激活参与计算,而不是所有专家都对每个输入进行计算,进一步降低对计算资源的需求。DeepSeek-V3模型一共有61层,其中58层是MoE层,每层设置257个专家,包括1个共享专家和256个路由专家,模型专家总数达到14906个。共享专家扮演全局知识处理的角色,始终参与所有输入的计算,能够捕捉数据中的普遍模式,为模型提供稳定的基础输出。路由专家专注处理特定类型的输入,通过门控机制按需激活。
DeepSeek-V3模型不仅通过优化创新Transformer架构降低算力需求,同时采取“FP8混合精度训练”和“对偶流水线机制(DualPipe)”提升GPU芯片的利用率。传统的训练方式通常采用32位浮点数(FP32)来表示模型参数和中间计算结果,这种高精度表示虽然能够保证计算的准确性,但在计算过程中需要消耗大量的计算资源和内存,并且在数据传输过程中会产生较高的通信开销。FP8混合精度训练对于一些对精度要求相对较低的计算任务,使用FP8格式进行计算。由于FP8格式的数据占用内存更少,并且在支持FP8计算的硬件设备上,其计算速度相比FP32和FP16有显著提升。对于一些对精度要求较高的操作,仍然使用较高精度的格式进行计算,以确保模型的训练稳定性和准确性。
在模型训练过程中,涉及到前向传播、反向传播以及参数更新等过程,这些过程中既包含矩阵乘法等数学运算,也包含不同计算节点之间的数据传输等通信操作。GPU通常按照一定的顺序在指令执行流水线中进行。然而,由于数学运算和通信操作的特性不同,它们在执行过程中可能会导致流水线出现“气泡”,即GPU在某些时间段处于空闲状态,降低了GPU的实际利用率。对偶流水线机制(DualPipe)将模型的计算过程划分为多个阶段,每个阶段包含数学运算和通信操作,当一个阶段的数学运算正在进行时,利用这个时间启动下一个阶段的通信操作,使得数学运算和通信操作在时间上尽可能重叠,减少了数学运算等待数据传输的时间。
DeepSeek-R1模型充分利用V3模型架构,针对复杂推理任务,引入强化学习技术,实现了与OpenAI o1模型相当的推理能力。强化学习是通过不断的试错过程和对结果的反馈进行学习,在长期内最大化累积奖励。传统的强化学习通常会有一个额外的批评模型来评估当前策略的好坏,然后根据评估结果来调整策略。然而,批评模型的训练既复杂又耗费计算资源。DeepSeek-R1使用GRPO算法,不需要批评模型,而是从当前策略中采样一组输出,然后根据这些输出的相对表现来调整策略,使表现较好的输出更有可能被生成,而表现较差的输出被抑制。DeepSeek-R1的推理训练分多个阶段,首先是冷启动阶段,利用精心设计的冷启动数据对DeepSeek-V3-Base进行微调,为模型提供初始的推理能力。接着在第一阶段的基础上,用GRPO算法强化学习,进一步提升模型的推理能力,并设计准确性奖励保证模型推理的正确,格式奖励和语言一致性奖励提升模型输出的可读性和流程性。随着强化学习训练的深入,模型思考时间增加,还自发“涌现”了诸如反思(重新审视和重新评估先前步骤)以及探索解决问题的替代方法等更加复杂的操作,表明模型在强化学习过程中能够不断自主提升推理能力。
美国经济成分中互联网、软件工具、金融等行业有相对较高的回报率,现阶段,美国AI应用率先与上述行业融合。与美国不同,我国拥有41个工业大类、207个中类、666个小类,是全世界唯一拥有联合国产业分类中全部工业门类的国家,特点是场景多、私有数据多,为AI+提供丰富的应用场景,赋能工业实现低碳绿色发展和产业升级。
诸如上述的工业应用场景有上百种之多,但AI+工业生产应用落地面临可靠性、数据隐私和工艺技术外泄风险以及经济性等挑战。DeepSeek模型在较低的算力资源上实现优异的性能,企业为模型本地化部署购买硬件支出大幅降低,而不依赖云端服务,数据的存储和处理均在本地完成,用户对数据拥有绝对控制权,可以自主决定数据的访问、使用与共享权限,从根源上杜绝了数据泄露风险。同时,本地化部署还能降低对网络的依赖,提高系统的稳定性和响应速度,DeepSeek模型可以在本地设备上即时响应请求,不受网络波动的影响,满足工业生产对可靠性和快速响应的要求。DeepSeek也降低了成本,其训练成本仅为同类闭源模型的1/20,模型推理成本也大幅降低,预计未来仍有进一步下降空间,将提高工业生产智能化升级的经济性。
根据目前大模型在企业侧落地交付实践,大模型能提升重复执行类和文本归纳类工业任务的处理效率,但受限于大模型现有技术瓶颈和企业数据质量问题,大模型在数据分析与决策支持等场景的效果仍需进一步提升。但得益于大模型推理阶段Scaling Law,人工智能技术能力仍有大幅提升空间,将扩大AI+新型工业化应用场景,将人工智能应用于研发,大幅提升研发效率,如预测蛋白质结构、设计高性能芯片、高效合成新药等。
时至今日,智能手机、电脑等终端产品正面临创新瓶颈,消费者更换周期拉长使相关产品消费需求乏力,通过将人工智能与手机、电脑等终端产品融合,成为个人生活助手,将促进手机、电脑等产品更新需求。同时,人工智能与汽车、人形机器人结合将创造新的产业。DeepSeek模型在低算力平台上的高效性,更契合在上述算力有限的终端产品上应用。
目前,AI大多以网页或独立应用的形式在手机上运行,无法获取设备上的数据或与其他应用交互,无法主动感知和操作。手机作为一种便携式移动设备,其硬件资源,如处理器性能、内存容量和电池续航能力等,与专业的服务器相比存在显著差距。DeepSeek-R1拥有6710亿参数,在进行复杂的推理任务时,手机的处理器很难在短时间内完成如此庞大的计算量,导致响应速度变慢,甚至出现卡顿现象,严重影响用户体验,能耗问题也不容忽视。知识蒸馏是将大模型学到的知识传递给小模型,如DeepSeek-R1通过知识蒸馏,将长链推理模型的能力传授给参数规模较小的小模型,实现模型本地部署。
DeepSeek将激发AI在手机端的创新应用,为用户带来更多新颖、实用的功能。在智能语音交互方面,基于DeepSeek的AI手机能实现更自然、流畅的多轮对话。传统的语音助手在多轮对话中往往容易出现理解偏差和上下文衔接不畅的问题,而DeepSeek强大的自然语言处理能力使 AI手机能够更好地理解用户的意图和上下文语境,实现更智能的交互。在个性化内容推荐方面,通过对用户的使用习惯、兴趣爱好和行为数据的深度分析,AI手机能够利用 DeepSeek的算法为用户推荐个性化的应用、新闻、音乐、视频等内容。
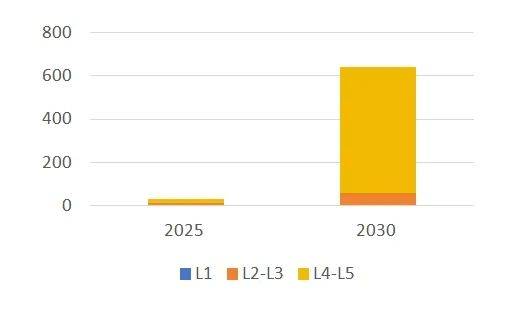
利用DeepSeek强大的语言理解、知识推理能力,对其进行微调,使其适应自动驾驶的特定任务需求。在微调过程中,使用大量的自动驾驶场景数据对DeepSeek模型进行训练,学习自动驾驶领域的专业知识和决策模式。例如,通过让DeepSeek学习不同路况下的驾驶决策案例,使其能够在面对类似场景时做出合理的决策,且其高效性也更适合部署在车辆计算平台。目前,业内专家预期L4级别的停车场自动泊车有望在2027年落地,高速公路L4级别自动驾驶也有望在2027年落地,L4级别商用车自动驾驶有望在2028年落地,L4级别市内自动驾驶需要到2030年前后落地。预计2025年中国自动驾驶市场空间290亿美元,其中L2-L3级自动驾驶市场空间130亿美元,L4-L5级市场空间160亿美元;预计到2030年中国自动驾驶市场空间将达6390亿美元,年复合增速85%,超过全球市场整体增速,其中,L4-L5级自动驾驶市场占比91%,年复合增速高达105%。
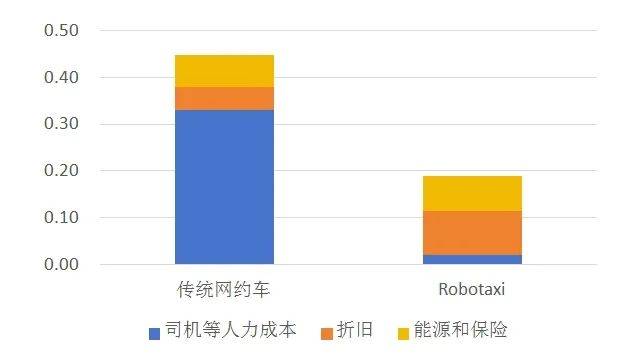
随着Robotaxi在2030年前后迎来规模化生产,预计Robotaxi每公里运营成本仅0.2美元/公里,远低于传统网约车0.45美元/公里,成本节省主要由人力成本贡献,Robotaxi每公里人力成本是0.02美元/公里,而传统网约车的人力成本是0.33美元/公里。Robotaxi的每公里折旧、能源和保险成本都将高于传统网约车,预计Robotaxi的折旧成本是0.095美元/公里,高于传统网约车的0.05美元/公里;Robotaxi的能源和保险成本是0.075美元/公里,高于传统网约车的0.067美元/公里。预计2030年中国Robotaxi市场空间2010亿美元,2025-2030年年复合增速111%,创造新的产业。
人形机器人硬件性能相对有限,如处理器的计算能力和通信带宽的不足,会导致机器人在执行复杂动作时,从接收指令到执行动作之间存在明显的延迟。数据采集与处理能力也需要进一步增强,在实际应用中,机器人需要实时采集大量的传感器数据,如视觉、听觉、触觉等信息,这些数据的维度高、噪声大,给数据处理带来了巨大的挑战。机器人还需要对采集到的数据进行实时分析和决策,以适应不断变化的环境和任务需求,目前的数据处理能力难以满足这一要求。现阶段,人形机器人成本高昂也限制了其商业化进程。DeepSeek模型在感知、决策和行动等方面对人形机器人的发展起到了重要的推动作用,且其模型高效性特点也更易于部署在人形机器人性能相对有限的硬件平台上。
随着深度学习、强化学习等人工智能技术的不断发展,人形机器人的智能化程度将得到极大提升。在未来,人形机器人将具备更强的自主学习能力,能够通过与环境的交互不断积累经验,快速学习新的技能和知识。这将使其能够更好地适应复杂多变的环境和任务需求,实现更加智能化的决策和操作。在工业制造领域,人形机器人将不仅局限于简单的搬运和焊接等任务,还可以通过学习大量的生产数据和工艺知识,自主优化生产流程,提高生产效率和质量。在服务领域,如在老年人的康复护理中,人形机器人可以陪伴老人进行康复训练,提醒老人按时服药,为老人提供心理支持和陪伴。康复机器人还能配备智能监测系统,能够实时监测患者的康复进展和身体状况,并根据监测结果调整康复训练方案,提高康复效果。在应急救援领域,在火灾救援中,人形机器人可以凭借其耐高温、耐烟雾的特性,进入火灾现场进行侦察和救援;在地震救援中,人形机器人具备强大的运动能力和适应能力,能够在倒塌的建筑物、瓦砾堆等复杂地形中行走、攀爬和穿越。从经济层面来看,人形机器人产业的崛起有望催生新的经济增长点,带动上下游产业链的协同发展。上游的核心零部件制造,如高精度减速器、伺服电机、传感器等,中游的机器人本体制造,以及下游的系统集成和应用服务,每个环节都蕴含着巨大的商业潜力。在社会层面,在老龄化日益严重的背景下,人形机器人可承担起养老护理、陪伴关爱等任务,缓解社会养老压力;在危险环境作业中,如消防、救援、矿山开采等,人形机器人可代替人类执行危险任务,保障人员生命安全。
DeepSeek通过软件算法创新突破算力瓶颈,特朗普2.0可能进一步收紧GPU芯片对华出口。据报道,美国正考虑限制英伟达H20芯片(符合现阶段出口管制要求的版AI芯片)出口。面对特朗普2.0加码科技封锁,我国也将推出支持政策应对。
不仅先进制程工艺,特朗普2.0可能对中国半导体产业实施全方位封锁。特朗普2.0延续其第一任期的投资限制、出口管制和实体清单等政策,与拜登政府更倾向于精准“点射”先进工艺和前沿技术不同,特朗普2.0可能采取全方位封锁,不仅针对先进技术和工艺,甚至可能波及成熟工艺。这意味着特朗普可能会对中国半导体产业实施无差别全面封锁,包括晶圆制造、芯片设计等环节,使中国企业难以获取关键的生产技术和设备。在“美国优先”政策基调下,特朗普2.0可能采取强硬手段迫使日本、韩国、中国台湾和欧盟等共同限制中国半导体产业,其第一任期时就以安全为由推动盟友限制采购华为5G方案。
相较于补贴,特朗普2.0更倾向于通过提高关税迫使半导体等制造业回流美国。拜登政府主要通过《芯片与科学法案》为芯片制造提供约527亿美元资金支持,鼓励企业在美国研发和制造芯片,提升美国国内芯片制造产能。特朗普政府则更倾向于通过设置关税门槛,迫使企业在美国设厂,而不是依靠补贴等方式推动芯片制造回流美国。
行业应用领域多点开花,AI教育、AI医疗等领域的成功实践,彰显AI赋能实体经济、改善社会生活的巨大价值。教育部于2024年3月启动 “人工智能赋能行动”,旨在多方面助推人工智能赋能教育,从优化教学过程、创新教育模式、提升教育评价科学性等维度发力。国家卫健委发布卫生健康行业人工智能应用场景参考指引,涵盖疾病预测、影像诊断辅助等多元场景,加速医疗智能化转型。
面对美国对我国人工智能技术封锁,我们预计2025年及其后可能出台相关支持政策,一是支持技术研发的政策,聚焦高端芯片、核心算法等关键短板领域。面向高校、科研院所及企业公开征集高风险、高回报前沿项目,激发创新活力,对取得突破性成果的团队给予高额奖励。二是完善数据法规,进一步细化数据分级分类管理标准。依据数据敏感程度、应用场景等维度,将数据分为不同等级,明确各级别数据收集、存储、使用、共享规范。三是人才培养与引进政策,推动高校加速人工智能学科建设。通过设置跨学科专业,融合计算机科学、数学、神经科学、行业应用知识,打造复合型人才培养体系。同时,出台海外高端人才引进专项政策,放宽签证限制,为顶尖人工智能人才开辟绿色通道,简化入境审批流程。
尽管目前我国半导体设备、材料等领域国产化水平仍有提升空间,但成熟制程产能全球占比将从2023年的29%提升到2027年的33%,中国成熟制程芯片供给能力大幅提高。中小容量的存储芯片、模拟芯片、MCU、电源管理芯片、模数混合芯片、CMOS传感器、传感器等主要采用成熟制程,中国工业、汽车电子、军事等领域供应链安全性相对较高。同时,中国是全球最大的半导体需求单一市场和增长极,将是中国反制美国制裁的有力手段,尤其对于供应来源相对多样的成熟制程半导体产业链。尽管目前先进制程芯片仍以进口为主,GPU等高性能计算、存储芯片、高端手机处理器等受限较大,但据金融时报报道,华为昇腾910C芯片良率已提升至40%左右,产线迈过盈亏平衡线,以华为昇腾和寒武纪为代表的国产AI芯片正逐步成熟,保障中国人工智能发展硬件基础。
DeepSeek推动了人工智能发展,今后仍将有其他科技企业从基础大模型、应用场景开发和智能硬件产品创新等多领域合力推动AI发展,但技术进步也将带来部分社会问题,如对就业市场的冲击、道德与法律难题、数据安全与个人隐私问题、互联网虚假信息泛滥等。
人工智能发展使一些重复性、规律性强的岗位被智能系统取代,但另一方面,也催生了一系列新兴职业,如深度学习岗位等。就业结构的变化加剧了社会贫富分化,可能导致社会矛盾的激化。发达地区由于拥有更好的科技资源和产业基础,能够吸引更多的人工智能企业和人才,就业机会相对较多;而欠发达地区在人工智能产业发展方面相对滞后,就业机会有限,也进一步加剧地区间的就业差距。
人工智能在多领域得到深入应用,推动各行业的数字化转型和创新发展,但也带来了道德问题,例如在招聘领域,算法偏见可能导致某些群体在求职过程中受到歧视。一些企业采用人工智能算法来筛选简历,然而,这些算法可能会受到训练数据中存在的性别、种族等偏见的影响,进一步加剧社会的不平等。
法律难题方面,人工智能发展带来责任归属难题。例如,当自动驾驶汽车发生事故时,确定责任归属变得异常复杂。有人认为自动驾驶技术开发者,应该对技术的安全性负责;也有人认为驾驶员在使用自动驾驶功能时,没有尽到足够的监管责任;还有人认为,事故可能是由于传感器故障、算法错误等多种因素共同导致的,难以明确单一的责任主体。责任认定的模糊性使得受害者难以获得合理的赔偿和救济,也给法律的适用带来了挑战。由于目前缺乏明确的法律规定和统一的标准,不同地区和国家对于自动驾驶事故责任的认定存在差异,这不仅增加了司法实践的难度,也影响了公众对自动驾驶技术的信任和接受程度。
数据是人工智能发展的核心驱动力,数据量越大、种类越丰富,AI模型的表现往往就越出色。人工智能对数据安全的影响主要集中在数据收集环节存在过度收集与非法收集的问题;数据存储环节面临黑客攻击威胁;在使用环节面临数据滥用与数据交易不规范的问题。人工智能对个人隐私的侵害主要有个人数据的滥用和泄露、AI系统就业偏见剥夺个人获得平等机会的权利以及AI对个人自由的监控。应对人工智能对数据安全与个人隐私的影响,除了在技术层面加强防范外,应加强法律监管力度。欧盟《人工智能法案》采用基于风险的分类监管方法,将人工智能系统分为不同风险等级,并针对不同等级实施相应的监管措施。在数据治理方面,企业需确保数据的质量、完整性和合法性,不得使用有偏见或未经授权的数据进行模型训练。在数据隐私方面,企业在收集、使用和存储个人数据时,必须获得用户的明确同意,并采取有效的安全措施防止数据泄露。
DeepSeek横空出世增强了我国发展自主可控人工智能产业的信心,推动了人工智能技术的发展,也对经济和社会发展发挥积极贡献。同时,我们也应认识到我国人工智能基础产业与美国仍有差距,且技术发展不可避免带来部分社会问题,因此我们提出如下四点政策建议。
尽管DeepSeek通过模型算法创新部分解决了算力不足的挑战,但随着人工智能技术发展,模型参数规模预计将大幅增加,对算力的需求也将倍增,拥有足够的算力对提升大模型能力天花板至关重要。在美国对我国禁运高端GPU芯片并封锁先进制程工艺背景下,建议从财税支持、科创金融体系等持续加大对先进半导体产业的研发支持。财税支持方面,如引导企业增加研发投入,通过税收优惠、补贴等政策措施,鼓励企业增加对半导体基础研究的投入,建立企业与高校、科研机构的合作机制,使企业在基础研究中发挥更大作用,如允许企业将一定比例的研发投入在税前扣除。科创金融体系支持方面,如探索设立科创政策性银行支持半导体产业发展;鼓励多元化股权投资共同支持半导体产业;发挥科技保险体系的风险兜底功能等。
我国在AI高端人才数量上与美国存在一定的差距,AI领域的人才数量与实际需求相比也明显不足。建议设立人工智能产业专项人才计划,吸引和培养一批高水平的科研人才,尤其在半导体、AI基础算法创新等基础领域加大人才吸引和培养,为他们提供良好的科研条件和发展空间;同时,加强国际人才交流与引进,制定优惠政策,吸引海外优秀人才回国工作或开展合作研究,积极参与国际学术交流活动。另外,建议改革评价机制,建立符合人工智能产业研究特点的评价机制,不以短期的论文数量和经济效益为主要评价标准,注重研究的科学性和潜在影响力,鼓励科研人员开展长期、深入的基础研究,并加强知识产权保护。
尽管长期维度人工智能发展将创造新的产业就业机会,但短期维度不少工作岗位将受到人工智能影响,势必在短期内冲击劳动力市场。建议加大对职业教育的投入力度,可以通过财政拨款、专项基金等方式,为职业院校和培训机构提供充足的资金支持,用于改善教学设施、更新教学设备,为学生和学员创造良好的学习环境。同时,建议完善社会保障体系缓解人工智能带来的失业风险,应加大对失业保险的投入,提高失业保险的覆盖范围和保障水平。扩大失业保险的参保范围,将更多的劳动者纳入失业保险体系,确保在失业时能够获得一定的经济支持。提高失业保险金的发放标准,根据当地的生活水平和物价指数,合理调整失业保险金的金额,保障失业人员的基本生活需求。还应加强对失业人员的再就业培训和创业扶持。设立专门的再就业培训基金,为失业人员提供免费的职业技能培训,帮助他们提升就业能力,适应新的就业市场需求。
我国高度重视数据安全和个人隐私保护,出台了《中华人民共和国个人信息保护法》等相关法律法规。为了进一步完善人工智能相关法律法规,应明确人工智能系统在数据收集、使用、存储和共享等环节的法律责任和义务。对于数据泄露、滥用等违法行为,应加大处罚力度,提高违法成本。在法律制定过程中,应充分考虑人工智能技术的特点和发展趋势,确保法律法规的适应性和前瞻性。还应加强国际间的法律协调与合作,共同应对人工智能时代数据安全和个人隐私保护面临的全球性挑战,避免出现法律冲突和监管漏洞。